Exploring Semantic Segmentation with Neural Networks
Written on
Chapter 1: Understanding Semantic Segmentation
Image segmentation stands as a core task within computer vision, alongside object recognition and detection. In the realm of semantic segmentation, our objective is to categorize each pixel of an image into distinct classes. Unlike standard image classification, where an entire image is assigned a single label, semantic segmentation focuses on labeling each individual pixel based on the various elements present in the image.

The above image serves as a practical illustration. Each pixel has been designated a specific label, represented by a unique color—red for individuals, blue for vehicles, green for foliage, and so on.
It's crucial to differentiate semantic segmentation from instance segmentation, where we identify and label different instances of the same class separately. For instance, in instance segmentation, each individual person would be assigned a distinct color.
Why is this detailed processing important? (And if you're not familiar with the term "frak," I suggest you catch up on Battlestar Galactica—it's a classic!) The necessity for such meticulous segmentation arises from its wide array of applications. A prime example is in autonomous vehicles, which require complete awareness of their surroundings, needing to interpret every single pixel. Other notable applications include robotics (both industrial and domestic), geosensing, agriculture, medical imaging, facial recognition, and fashion.
If you're intrigued, let's delve into how we can tackle this task. It's not overly complex.
Chapter 2: The Role of Deep Learning
Deep neural networks have undeniably transformed the field of computer vision, particularly in image classification. Since 2012, their performance has greatly surpassed that of earlier methods, proving that machines can outperform humans in this domain. Consequently, similar techniques have been adapted for semantic segmentation, and they have indeed proven effective.
Convolutional Neural Networks (CNNs) have become the industry standard for addressing these challenges. Rather than exploring the historical evolution of various architectures, let's focus on the current state-of-the-art as of 2019.
To clarify our objectives:
- Each pixel must be allocated to a specific class and color.
- The dimensions of the input and output images must match precisely.
- Each pixel in the input must correlate with a pixel in the output at the same location.
- We require pixel-level precision to differentiate between various classes.
With these criteria established, we can examine the architecture: Fully Convolutional Network (FCN).
FCNs are constructed solely from convolutional and pooling layers, eliminating the need for fully connected layers. The initial design involved stacking identical-sized convolutional layers to map the input image to the output.
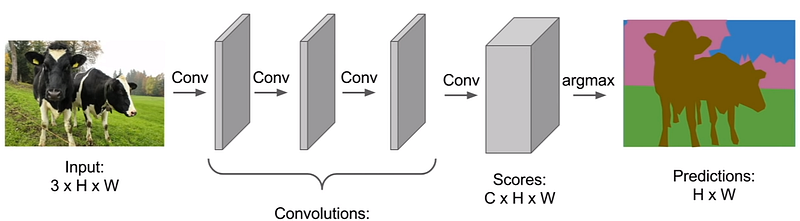
While this approach yielded satisfactory results, it came with significant computational demands. The challenge was that incorporating downsampling or pooling layers would disrupt the spatial localization of the instances. To preserve image resolution, numerous layers were required to capture both low-level and high-level features, making the process inefficient.
To address these issues, an encoder-decoder framework was proposed. The encoder utilizes traditional convolutional networks like AlexNet or ResNet, while the decoder features deconvolutional and up-sampling layers. The purpose of downsampling is to gather semantic/contextual details, whereas upsampling aims to restore spatial information.
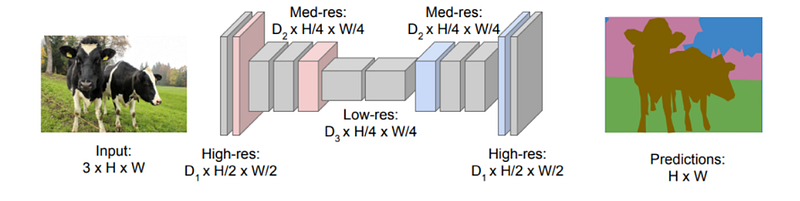
This architecture significantly reduces both time and space complexity but can also affect the quality of the output. The encoder's reduction of image resolution may lead to less distinct edges in the segmentation, obscuring the boundaries between different elements.
Enter the solution: Skip Connections. These connections allow for the direct transfer of information from earlier layers of the encoder to the decoder, bypassing the downsampling layers. This mechanism enhances the detail of the segmentation, resulting in more accurate shapes and boundaries.
Chapter 3: The U-Net Architecture
Building on the concepts of encoder-decoder structures and skip connections, the U-Net architecture emerged. U-Net introduces symmetry by enlarging the decoder to match the encoder's size and substituting the summation operation in skip connections with concatenation.
This symmetry enables the transfer of a greater volume of information from downsampling layers to upsampling layers, which improves the output's resolution.
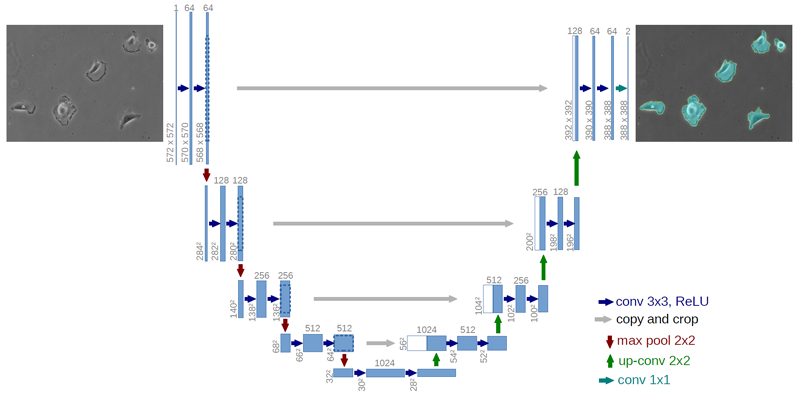
Originally designed for biomedical image segmentation, U-Nets have been adapted for various applications, often incorporating fully connected layers or residual blocks.
To grasp the U-Net concept fully, let's write some code to demonstrate its simplicity. We will utilize Python and the Keras framework for ease of implementation.
Do you think I'm joking? That's really all it takes! A combination of convolutional, pooling, and upsampling layers, along with a few concatenations to facilitate skip connections. Simple, right?
However, there's still a significant amount of work ahead, including preprocessing our input data, augmenting it, and most importantly, gathering it. Constructing ground-truth segmentations is a challenging endeavor. For each input image, we need a corresponding segmentation to measure the error. How can we create these ground-truth segmentations? Manually? Possibly. Through a well-crafted script? Maybe. One thing is clear: it's not an easy task.
Additionally, other innovative methods for semantic segmentation exist, most of which build upon the foundations of FCN and U-Net architectures. Some notable examples include:
- DeepLab, which employs atrous convolutions
- Pyramid Scene Parsing Network
- Multi-path Refinement Networks
- Global Convolutional Networks
Semantic segmentation remains a vibrant area of research due to its significance and relevance in real-world scenarios. We anticipate a surge of new publications in the coming years. The intersection of computer vision and deep learning is exhilarating and has driven remarkable advancements in complex tasks. Do you think Tesla's autonomous vehicles could have covered 1.2 billion miles without deep learning? Personally, I don't think so. Let's see what the future has in store for us!
If you have thoughts, questions, or want to stay updated with my latest content, feel free to connect with me on LinkedIn, Twitter, Instagram, GitHub, or visit my website.
This video, titled "Beginner's Guide to Semantic Segmentation With Convolutional Neural Networks," offers a great starting point for those new to the topic, providing foundational insights into how CNNs can be utilized for semantic segmentation.
The second video, "Fully Convolutional Networks for Image Segmentation | SciPy 2017 | Daniil Pakhomov," dives deeper into FCNs, showcasing their application in image segmentation and offering practical examples.