Optimizing Data Science Practices for Enhanced Efficiency
Written on
Chapter 1: The Role of Data Science in Automation
Data science serves as a critical pillar in the realm of automation, enabling organizations to transition from manual processes to automated systems while also providing analytical insights on collected data. By integrating various disciplines, such as artificial intelligence, statistics, and data analysis, data science helps in extracting valuable insights from user, organizational, and client data. This information is essential in determining the key metrics to focus on and in visualizing different employee roles through graphical representations.
Data scientists have the capability to gather information from a multitude of sources, including customers, sensors, mobile devices, and online platforms, to unearth actionable insights. By aggregating and transforming this data, they can identify trends and offer informed recommendations to business leaders. While data science employs various tools and methodologies to manage dynamic datasets, the outcomes are not always consistently reliable.
Chapter 2: Best Practices in Data Science
Section 2.1: Importance of Data Versioning
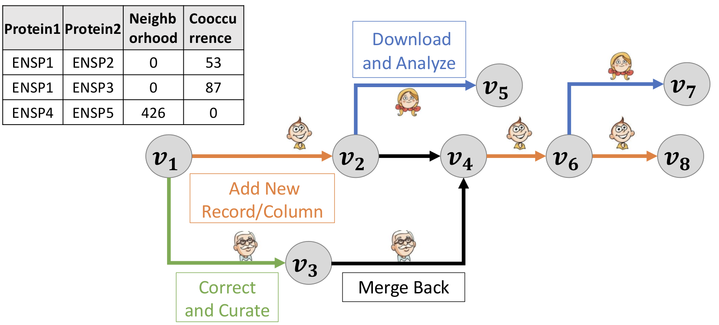
Implementing data versioning is crucial for ensuring repeatability, reliability, and compliance in data management. Each version of a dataset represents a distinct snapshot over time, allowing users to track how datasets evolve. Access to historical data facilitates various analyses, such as forecasting organizational performance across different periods.
Furthermore, maintaining multiple data versions aids in fulfilling regulatory obligations. In machine learning, having a rich dataset empowers models to learn effectively from diverse data types. Data versioning also allows developers to review historical changes, facilitating better integration of improvements and ensuring all application updates function as intended.
Section 2.2: Isolating and Identifying Business Metrics
Organizations must identify and analyze various metrics relevant to their specific business models. Adjusting these metrics can significantly enhance organizational performance. For instance, measuring the time spent on tasks and their accuracy can provide insights into the efficiencies gained through automation versus manual processes.
By categorizing the time invested in both automated and manual tasks, businesses can better understand the impact of automation on productivity and cost-efficiency. This analysis helps determine whether to maintain a manual approach or fully embrace automation, ultimately clarifying key performance indicators (KPIs).
Section 2.3: Adaptation and Continuous Improvement
Data-driven initiatives cannot remain static, as shifting business priorities often require data scientists to revisit and refine their models. For example, the shift to remote work during the COVID-19 pandemic necessitated a reevaluation of previous operational models. New algorithms must be developed or existing ones adjusted to reflect this new normal.
Ongoing monitoring of these algorithms is essential, with performance thresholds established to determine their effectiveness. Each time a data scientist is presented with new business objectives, they must adapt their models accordingly, creating a cycle of continuous improvement.
Section 2.4: Evaluating Algorithm Efficiency
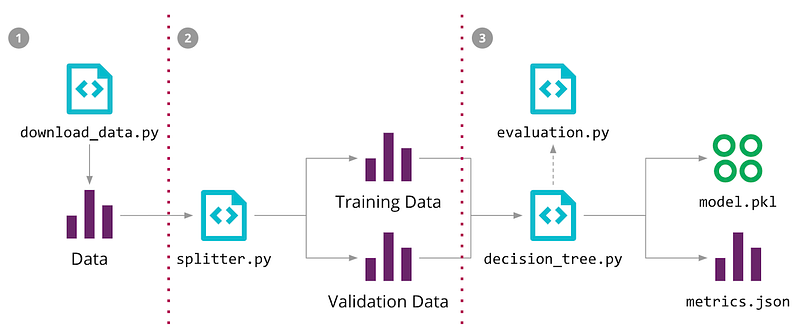
Algorithms are systematic approaches to problem-solving, predominantly utilized in programming. When addressing a problem, multiple algorithmic solutions may exist, but selecting the most efficient one is paramount. Data scientists benefit from comparing various machine learning algorithms to ascertain the most effective for their specific goals.
By evaluating methods such as random forests, decision trees, and image recognition algorithms, data scientists can determine which performs best under identical conditions. This step is vital for achieving optimal results, and utilizing diverse algorithms for distinct tasks can lead to enhanced outcomes. For instance, accuracy rates for different algorithms in image processing can vary significantly:
- Random Object Algorithm: 92.15%
- Decision Tree Algorithm: 94%
- Image Identifier Algorithm: 99%
Given these results, it's clear that the Image Identifier Algorithm delivers superior accuracy, making it the preferred choice for image processing tasks.
Conclusion
Numerous strategies exist to enhance the effectiveness of data science processes. In this discussion, we've highlighted key practices that can significantly improve efficiency and lead to superior outcomes for data scientists. Given the complexity of data science, which often relies on artificial intelligence and algorithmic calculations, it is essential to select the appropriate algorithms based on business needs to ensure optimal performance.