Exploring Scalable Loki Deployment on Kubernetes
Written on
Understanding Loki's Architecture
In previous discussions, we've delved into Loki, which is rapidly gaining traction and becoming a regular choice for developers. Given its growing popularity, it's worth exploring the architecture of Loki in more detail.
Loki offers several advantages that make it a top candidate for constructing a Log Aggregation Stack. One of its key strengths is scalability, which allows for various deployment models based on component selection and organization.
Components of Loki
The architecture consists of several crucial components:
- Ingester: Handles the writing of log data to long-term storage solutions (such as DynamoDB, S3, Cassandra) and serves log data for in-memory queries.
- Distributor: Manages incoming log streams from clients, acting as the initial step in the write path.
- Query Frontend: An optional service that provides API endpoints for queries and can speed up the read process.
- Querier: Executes queries using the LogQL language, retrieving logs from both ingesters and long-term storage.
- Ruler: Continuously assesses a set of configurable queries and performs actions based on the outcomes.
These components can be grouped in different configurations, leading to various deployment topologies, as illustrated below:
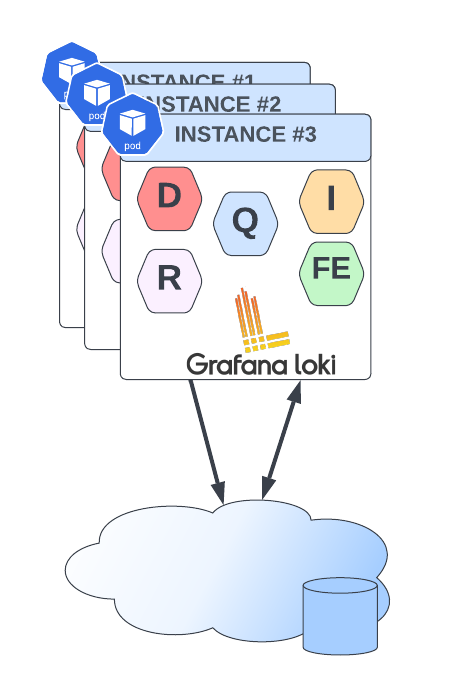
Deployment Models
- Monolith: All components operate within a single instance, making it the simplest configuration and suitable for a starting point of 100 GB per day. While this model allows for scaling, it impacts all components simultaneously and requires a shared object state.
- Simple Scalable Deployment Model: This intermediate model can scale to handle several terabytes of logs daily. It separates components into distinct read and write profiles.
- Microservices: In this configuration, each component is managed independently, providing the flexibility to scale each part as needed.
Defining the deployment model for each instance is straightforward and hinges on a single parameter known as "target." Depending on its value, the system will adopt one of the aforementioned models:
- all (default): Functions as a monolith.
- write: Represents the write path in the scalable deployment model.
- read: Pertains to the reading group in the scalable deployment model.
- Individual components: Values to deploy specific components in the microservice model (e.g., ingester, distributor, query-frontend, etc.).
The "target" argument is particularly useful for on-premises deployments. For those utilizing Helm for installation, Loki provides different Helm charts tailored for each deployment model:
All Helm charts operate on the principle of defining each instance's role using the "target" argument, as depicted in the following image:
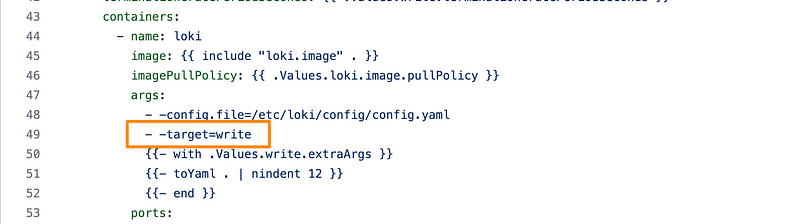
Chapter 2: Deployment Insights
This video titled "New in Grafana Loki 2.4: The Simple Scalable Deployment Mode" provides insights into the latest features and enhancements in Loki, focusing on deployment strategies.
Another informative video, "Simple, scalable deployment for Grafana Loki and Grafana Enterprise Logs," discusses effective deployment practices for Loki, ensuring optimal performance and scalability.